Can we find causal events in reinforcement learning using attention?
by Mykyta Baliesnyi, supervisor: Oriol Corcoll
This is a study project for the Computational Neuroscience course at the University of Tartu.
Motivation
Humans and other intelligent animals learn about causality in the world pretty quickly by automatically assigning credit to the events and actions that we think caused something to happen.
For example, as a kid, when we first get burnt by fire, we quickly assign the feeling of pain to our action of putting the hand above the fire. When the delay between the past action and the current result gets larger, as in understanding that eating an unripe apple is what caused a gurgling and hurting stomach, assigning credit becomes harder — but we can still usually do it successfully.
But how exactly does the brain identify events that are relevant among all the millions things that could have happened in between?
Effective credit assignment in artificial intelligence has been a long-standing problem. If one of the current machine learning approaches was that person who ate an unripe apple, it could easily take several dozens of trials until it understands the connection between the events.
In this project, I would like to better understand how credit assignment might be implemented by modeling this process in the context of reinforcement learning (RL).
Methodology
Reinforcement Learning
Reinforcement learning is a type of machine learning, like supervised and unsupervised, but with a focus on learning through continuous interaction with an environment. Instead of learning to make the most accurate predictions on a static dataset, reinforcement learning is about learning, through trial and error, how to behave in a world so as to get the most reward.

This paradigm is inspired by how humans and other intelligent animals learn, and so, many think of it as one of the most promising ways to understanding decision making and learning, and eventually developing general artificial intelligence (AGI).
Self-Attention
The self-attention mechanism is an alternative to recurrent neural networks, which allows learning from sequential data by adaptively “paying attention” to different moments of the past at each step. It often works much better for capturing long-term dependencies than recurrent neural network architectures such as LSTMs and GRUs. This is especially useful in the context of reinforcement learning, where interaction with an environment can last anywhere from hundreds to thousands of steps, and some event that happened a very long time ago can determine the agent’s reward in the present moment.
In this paper, the authors used a self-attentional neural network to predict the agent’s rewards just from seeing what the agent observes and does in the environment. They showed that using this attentional model to create a denser reward signal improved the sample efficiency of an arbitrary RL agent even in relatively novels environments. For this project, I’m going to re-implement the reward prediction model they used and apply it in a different environment to see how generalizable this approach is. The key question I’d like to explore is:
Can a self-attentional neural network identify important past events?
Environment
For an environment, I chose the Mayan Adventure environment for MLAgents in Unity. This is a small 3-D virtual world with a set of traps and a cute cubic agent in a cool Indiana Jones hat.
The goal in the environment is to stay alive and obtain the golden statue of Maya. Along the way, there are buttons that can turn our Indiana Jones agent into one of two states: Rock or Wood. Turned into Wood, the agent is light enough to go over bridges but will burn the instant it touches fire. Turned into Rock, the agent can go through the fire untouched but if it steps on a bridge, it will collapse and the agent will fall down.
To make training easier and incentivize the agent, there are some randomly located diamonds that act as intermediate rewards. Stepping on the diamonds and getting the golden statue all give +1 reward, while falling off the area or getting burned by fire give a -1 reward, instantly finishing the episode. A tiny negative reward is given to the agent at each step to incentivize it to finish the episode faster.
For observations, the environment uses a vector of what’s called ray casts. Think of those as invisible lasers shooting in several directions and telling the agent what objects are around it and how far away. The observations were stacked together so that a single observation contains information from the 6 most recent timesteps. In addition, the agent has access to the state it is turned into, either rock or wood, and to its speed and direction of movement.
Approach
To answer the key question, I first trained a reinforcement learning agent to get moderately good at solving the environment. The agent is trained with the Proximal Policy Optimization (PPO) algorithm. PPO is a very common learning algorithm, being easy to tune and giving good performance with relatively little hyperparameter tinkering. I didn’t have to implement the learning algorithm, as it was provided by the MLAgents Python package.

The training process was organized in 4 levels of curriculum learning, with progressively higher complexity. This is an effective method of regularizing and speeding up the learning of the agent that tries to master a complex task. It’s also just a natural way to learn for humans, starting from the very basics, and moving on to more high-level and complicated things as you get better.

Next, I implemented and trained the self-attentional model to predict rewards based on a sample of episodes of the agent interacting with the environment.
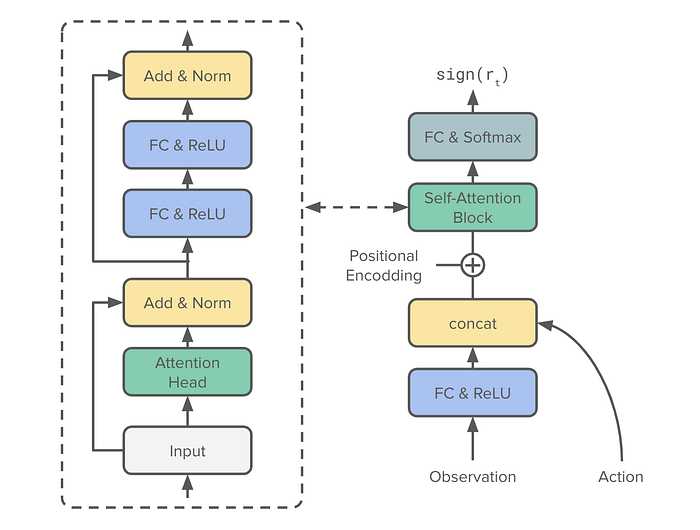
For implementing and training the model, I used PyTorch. I modified the original model from the paper by replacing the convolutional block with a simple linear layer. We don’t need convolutional layers because the observations in the environment are in 1-D vector form.
Since most of the time, the agent gets the reward of zero(I treated the tiny negative reward at each step as zero), with few events giving positive or negative rewards, the dataset for the reward prediction task is extremely imbalanced. I used a weighted Sequential CrossEntropy loss with class weights of 0.499 for positive and negative rewards and 0.02 for zero rewards, in accordance with the original paper.
Since we feed the full episode to the model at once, we need to prevent the model from “cheating” by looking into the future to know which reward it should predict now. This is done by applying a mask to the output of the self-attention that zeroes out future attention at future timesteps, such that the model can only learn from the past.
Expectations
Ideally, we would like the model to identify past events of pressing the buttons as important when predicting the agent’s reward as it steps onto a bridge or into the fire. Specifically, the really important event should be around the button that was pressed the last.
However, our observation space includes the information about the full agent state, including whether the agent is currently Rock or Wood, following what’s called the Markov Property. This makes it really unnecessary to remember or attend to those past events, as all the information the agent needs, was with it in the most recent moment. Because of this, the model might pay most of its attention to just the recent moment, and we would need to artificially limit what information the model has access to in order to force it to look into the past.
Results
Models’ performance
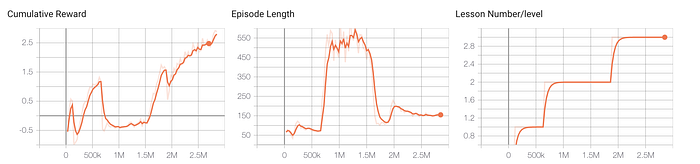
I trained the agent to a level of moderately good performance where it was successful in most but not all episodes. As you can see from the cumulative reward plot, the agent’s performance was still continually improving. I stopped the training at this moderately-good performance level to make sure the agent is not perfect at solving the environment and sometimes gets negative rewards. Otherwise, the model would only have to learn to assign positive rewards and probably would not pay attention to events that are important for such good performance. Think of it this way: when somebody is good at playing tennis, it’s often hard for them to explain what is important to make a great shot — they just do it automatically.
The training took about 2 hours on my laptop’s CPU, which is quite fast and is in part due to the small observation size, and running 32 copies of the agent in parallel. Here is a video of the agent successfully solving the task:
To train the attention model, I used 33 thousand episodes of the agent above interacting with the environment and chose the model with the lowest validation set loss after ten epochs.
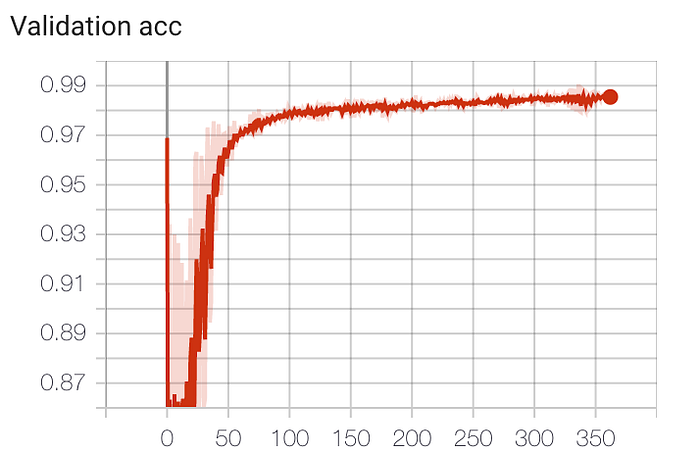
Following are per-class F-1 score accuracy metrics of the resulting model on a separate held-out evaluation set:
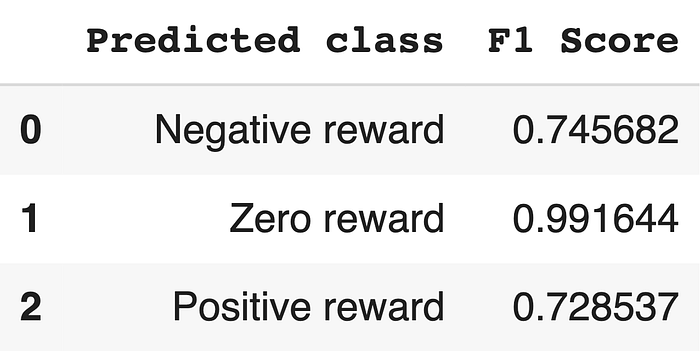
We can see that the F-1 score for zero rewards is almost perfect, while negative and positive rewards have lower values.
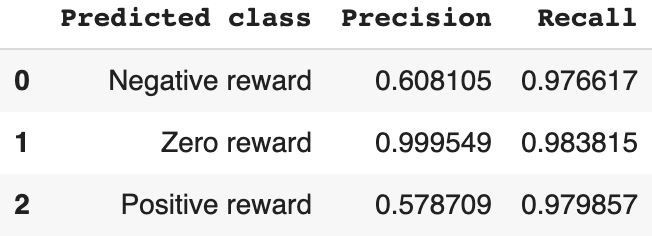
Precision and recall, which make up the f-1 score, show why the results are this way. All classes have a very high recall, but negative and positive rewards have lower precision — which basically means the model assigns negative and positive values more often than it should.
This happens, for example, when the agent steps on a diamond which gives a positive reward. The model might get confused about whether the agent picked up the diamond just now or in the previous step, and predicts the positive rewards twice. A similar thing happens with negative rewards when the agent falls or steps into the fire.
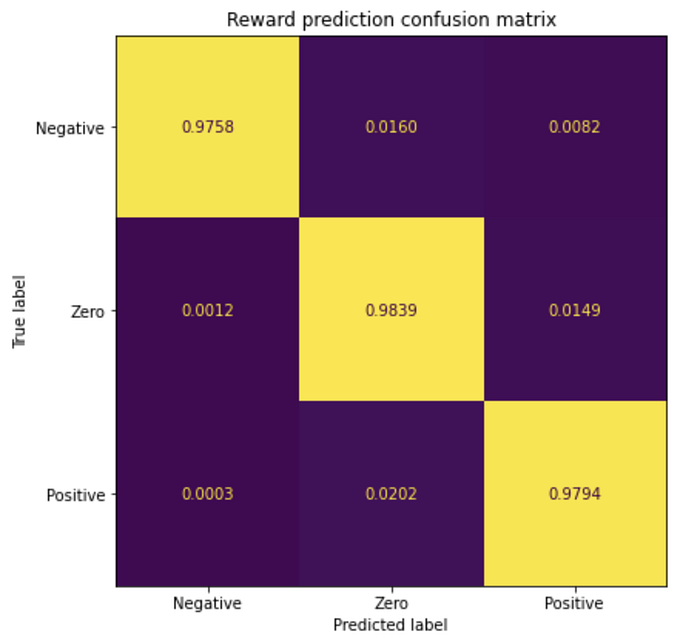
The confusion matrix shows that most of the time, however, the classes are predicted correctly.
Attention to important events
As expected, most of the attention is usually concentrated in the few most recent moments, because they are enough to predict the reward well (the Markov property). However, sometimes the model does attend to earlier moments as well:
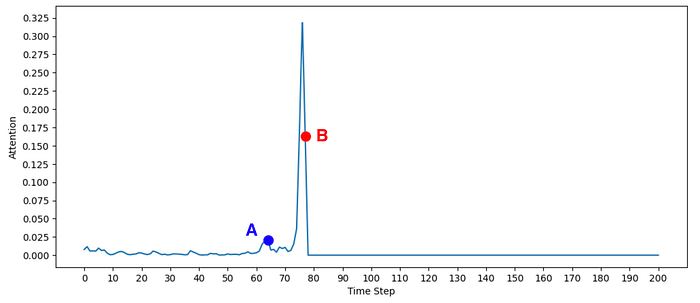
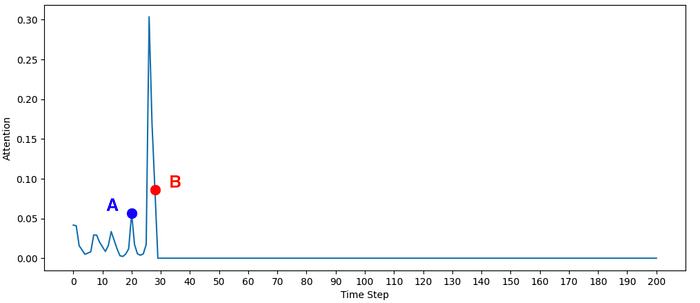
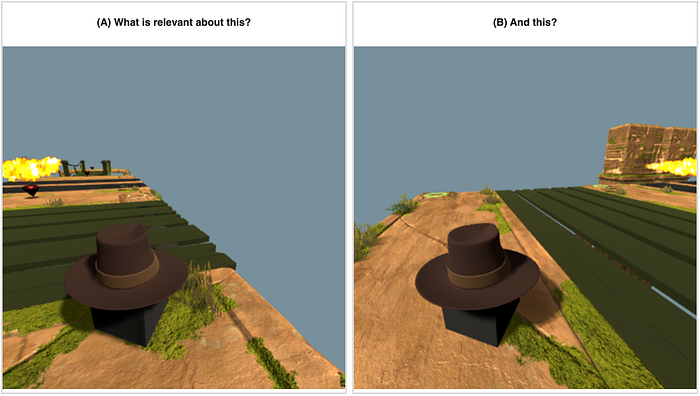
We can see that although the attention value is quite small, there’s relatively more attention paid to moment A than to the rest of the past. Below you can see the screenshots from steps A and B.

As hoped for, there is increased attention to the past moment of pressing the Rock button (A) when walking into the fire (B).
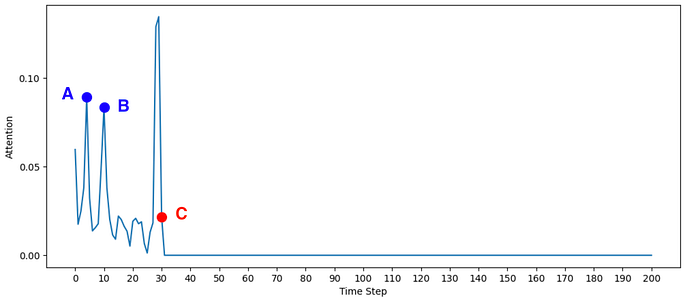
Now, here is an example where attention is not concentrated around the most recent moment:
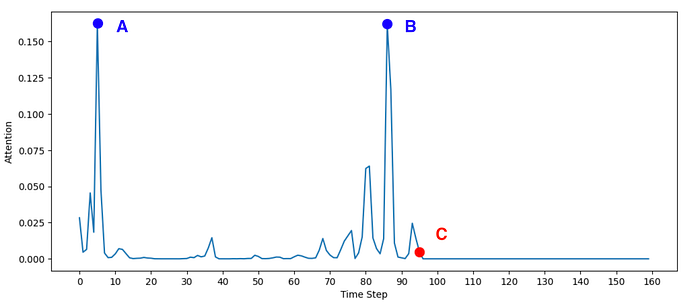
In this case, the agent was about to step on a bridge (C) and, as we would hope, the model paid increased attention to the moment the agent turned into Wood (B). Somewhat interestingly, the model also paid a lot of attention to an early moment in the episode, when the agent was about to step on another bridge (A).

This might be explained by the fact that the earlier moment has a very similar observation to the current moment, and the model regarded it as relevant in some way.
Here is an example where the model predicted a bad outcome before it happened:

In this case, the agent forgot to turn itself into Wood and was about to step on the bridge. Very intelligently, the model shows increased attention around the moment when the agent turned itself into Rock to walk through the fire about 25 steps earlier. Nice job, attention! 🎉

Pitfalls
It might look as though the model works really well, as it consistently identifies relevant events. Is that really so? Yes and no. If we take a more detailed look at the charts above, we can see the model could be quite inconsistent. Sometimes it attends to the moments before pressing the button, and sometimes to the moments after pressing it. In other cases, the model assigns a lot of weight to a truly important earlier event at one step and then pays a lot more attention to some seemingly unrelated events just two steps later. Consider the following example:

We again can see that the model identifies the moment around pressing the button as important before stepping on a bridge. However, see what happens in just two steps:
What happened? Although the agent is still just stepping on the bridge and attends to the moment of pressing the button, it started paying a lot more attention to some very early moments (A) and (B). Can you explain in what way are these moments important?
As suggested earlier, it could be that the model is picking up on the fact that these moments were very similar to the current moment. However, why didn’t it pick it up just two steps ago, and how exactly is the similarity between two moments relevant for predicting the reward? It’s hard to answer that question, as neural networks are still pretty much a block-box and are hard to interpret.
Future work
There are multiple additional questions one can ask beyond just identifying important events. For example, would the attention model pay more attention to relevant events if I were to restrict the information it has access to in the present? Would it become more consistent in identifying the exact timings of important events with relative positional encoding? It is also interesting to see if can we get faster learning and generalization ability as the authors of the approach got, in this different environment.
Beyond repeating what the authors have done, I would be interested to test the limits of this approach and try to apply it in more varied contexts to see where it breaks. If it doesn’t break, it might be used as something similar to the useful biases in human brains. Similar to how these biases developed over millennia of evolution and are given to humans “for free” before they start training their brains’ neural networks, we might use this approach to pre-fill reinforcement learning agents with a type of useful biases that make them learn and make better decisions faster.
Conclusions
Soo… can the neural self-attention mechanism help us identify important events? Again, yes and no. The model suffers from what neural networks generally suffer from — limited interpretability. It could be the case that some moments the model attends to that we do not deem important are actually relevant in some way that we overlook. But we can’t benefit from these insights directly without understanding what that connection is.
However, we might not really need to understand that. The only thing we really care about is for the model to allow us to decrease the number of events in the past we have to look at while considering if they are relevant. From the charts above we can see that in this environment usually only up to a dozen moments are attended to. The model nails its task. Furthermore, in most cases, the model does pick up on the truly important events, such as paying a lot of attention to the moments of pressing a button.
Acknowledgments
Thanks to everyone who helped make this project happen:
- Oriol Corcoll, for suggesting the topic and guiding me along the way
- Raul Vicente, for the amazing teaching of the Comp. Neuroscience course
- Andy Kotliarenko, for having my back in important moments
- Kirill Savchenko, for guiding me on attention visualization
- Hilary Emenike, for proofreading the article
- European Regional Development Fund, the Archimedes Foundation, and the University of Tartu, for support by the Dora Scholarship.
